Part 1 - Intro to Search Problems - Uninformed & Informed Search Algorithms (with Python)
Video: https://youtu.be/WbzNRTTrX0g
#CS50x #AI #Python #Algorithms
Read more here
Table of Contents:
B) Introduction to the "Search" Problem 🔍🧩
But today it will begin our conversation with Search.

This problem of trying to figure out what to do when we have some sort of situation that the computer is in, some sort of environment that an agent is in, so to speak. And we would like for that agent to be able to somehow look for a solution to that problem.

B.1) Examples of Search Problems (Puzzles)
Now, these problems can come in any number of different types of formats.
One example, for instance, might be something like this classic 15 puzzle with the sliding tiles that you might have seen,

where you're trying to slide the tiles in order to make sure that all the numbers line up in order. This is an example of what you might call a search problem.
The 15 puzzle begins in an initially mixed up state and we need some way of finding moves to make in order to return the puzzle to its solved state.

But there are similar problems that you can frame in other ways.
Trying to find your way through a maze, for example, is another example of a search problem.

You begin in one place, you have some goal of where you're trying to get to, and you need to figure out the correct sequence of actions that will take you from that initial state to the goal.
And while this is a little bit abstract, anytime we talk about maze solving in this class, you can translate it to something a little more real world, something like driving directions.

If you ever wonder how Google Maps is able to figure out what is the best way for you to get from point A to point B and what turns to make, at what time, depending on traffic, for example. It's often some sort of search algorithm. You have an AI that is trying to get from an initial position to some sort of goal by taking some sequence of actions.
So we'll start our conversations today by thinking about these types of search problems and what goes in to solving a search problem like this in order for an AI to be able to find a good solution.
In order to do so, though, we're going to need to introduce a little bit of terminology...
B.2) Components of the Search Problem (agent, state, actions, models, goal test and path cost)
Let’s first define some terms:
- Agent: The entity making decisions. This could be a robot, a character in a game, or even a piece of software. It observes its environment and makes decisions based on what it perceives.

- State: A representation of the agent's current situation in its environment. For example, in a maze, the state could describe the agent’s position.

In our previous example, the "states" in the 15 tile puzzle are the configurations of the tiles,

- Initial State: Where the agent starts.

For example, our 15 tile puzzle can have this initial State,

- Actions: The possible moves or decisions the agent can make from a given state. For example, in a maze, actions might include moving up, down, left, or right.

For example, our 15 tile puzzle can have 4 actions applied to a single tile,

- Transition Model: A description of what happens when an action is taken. In the maze example, if the agent moves up, the transition model would describe how the agent's position changes.

For example, our 15 tile puzzle can have this Result after applying an actions to a specific state,

- State Space: The set of all possible states the agent could potentially reach by performing actions. This could be vast, especially in complex problems.

For example, our 15 tile puzzle can draw a diagram,

We can simplify this diagram to a "graph" made with nodes and arrows,

- Goal Test: A way of determining if the agent has reached its objective. In a maze, for example, this would be checking whether the agent has reached the exit.

- Path Cost: A numerical value representing how "expensive" a particular series of actions is. Often, we want our agent to not only reach its goal but to do so in the least costly way. Ask yourself, what is its cost in terms of money, or time, or some other resource that we are trying to minimize our usage of.

We can represent the Path Cost graphically with the State Space graph.

Imagine that each of these arrows, each of these actions that we can take from one state to another state, has some sort of number associated with it,

that number being the path cost of this particular action, where some of the costs for any particular action might be more expensive than the cost for some other action, for example.
Although this will only happen in some sorts of problems. In other problems we can simplify the diagram and just assume that the cost of any particular action is the same.

And this is probably the case in something like the 15 puzzle, for example, where it doesn't really make a difference whether I'm moving right or moving left.
The only thing that matters is the total number of steps that I have to take to get from point A to point B. And each of those steps is of equal cost (e.g. a cost of just "1").
B.2.1) Types of Solutions for the Search Problem
So this now forms the basis for what we might consider to be a search problem.
Summary:
A search problem has some sort of initial state, some place where we begin, some sort of action that we can take or multiple actions that we can take in any given state, and it has a transition model, some way of defining what happens when we go from one state and take one action, what state do we end up with as a result. In addition to that, we need some goal test to know whether or not we've reached a goal. And then we need a path cost function that tells us for any particular path, by following some sequence of actions, how expensive is that path.

The main goal is to find a "solution", where a solution in this case is just some sequence of actions that will take us from the initial state to the goal state.


And, ideally, we'd like to find not just any solution, but the optimal solution, which is a solution that has the lowest path cost among all of the possible solutions.


And in some cases, there might be multiple optimal solutions, but an optimal solution just means that there is no way that we could have done better in terms of finding that solution.
B.3) Data from the Search Problem (defining the Node Data Structure - ⚪)
So now we've defined the problem. And now we need to begin to figure out how it is that we're going to solve this kind of search problem.
And in order to do so, you'll probably imagine that our computer is going to need to represent a whole bunch of data about this particular problem.

We need to represent data about where we are in the problem. And we might need to be considering multiple different options at once.
And oftentimes when we're trying to package a whole bunch of data related to a state together, we'll do so using a [[data structure]] that we're going to call a [[node]].
What are nodes? - Nodes are the fundamental building blocks of many [[data structures]]. They form the basis for [[linked lists]], [[stacks]], [[queues]], [[trees]], and more.
An individual [[node]] contains data and links to other nodes. Each [[data structure]] adds additional constraints or behaviours to these features to create the desired structure.

Consider the node depicted above. This node (node_x) contains a piece of data (the number 10) and a link to another node (node_y)
Read more here
A [[node]] is a [[data structure]] that is just going to keep track of a variety of different values, and specifically in the case of a search problem, it's going to keep track of these four values in particular.

B.3.1) Data tracked by the Node (current state, parent state, action and path cost)
Every node is going to keep track of:
- a state, the state we're currently on.

- is also going to keep track of a parent. A parent being the state before us, or the node that we used in order to get to this current state.

And this is going to be relevant because eventually, once we reach the goal node, once we get to the end, we want to know what sequence of actions we used in order to get to that goal.
And the way we'll know that is by looking at these parents to keep track of what led us to the goal, and what led us to that state, and what led us to the state before that, so on and so forth, backtracking our way to the beginning so that we know the entire sequence of actions we needed in order to get from the beginning to the end.
- The node is also going to keep track of what action we took in order to get from the parent to the current state.

- And the node is also going to keep track of a path cost. In other words, it's going to keep track of the number that represents how long it took to get from the initial state to the state that we currently happen to be at.

And we'll see why this is relevant as we start to talk about some of the optimizations that we can make in terms of these search problems more generally.
So this is the [[data structure]] that we're going to use in order to solve the problem:
B.4) Strategy to Solve the Search Problem (defining the Frontier Data Structure - 🗃️)
And now let's talk about the approach, how might we actually begin to solve the problem?
Well, as you might imagine, what we're going to do is we're going to start at one particular state and we're just going to explore from there.

The intuition is that from a given state, we have multiple options that we could take, and we're going to explore those options. And once we explore those options, we'll find that more options than that are going to make themselves available. And we're going to consider all of the available options to be stored inside of a single frontier.
frontier- a [[stack]] or [[queue]] to keep track of the [[nodes]] to be explored.

The frontier is going to represent all of the things that we could explore next, that we haven't yet explored or visited. And we will see what happens when we use the frontier as a stack vs using it as a Queue.
Step1) Start with Initial State
So in our approach, we're going to begin this search algorithm by starting with a frontier that just contains one state. The frontier is going to contain the initial state because at the beginning, that's the only state we know about.

And then our search algorithm is effectively going to follow a loop. We're going to repeat some process again and again and again.
Step2) Loop: Check if "no solution" condition occurred
The first thing we're going to do is check if the frontier is empty, if that is the case then there's no solution.

And we can report that there is no way to get to the goal.
And that's certainly possible. There are certain types of problems that an AI might try to explore and realize that there is no way to solve that problem. And that's useful information for humans to know, as well.
So if ever the frontier is empty, that means there's nothing left to explore, and we haven't yet found a solution so there is no solution. There's nothing left to explore.

Step3) Loop: Remove a Node from the Frontier
If the frontier is not empty, what we'll do next is we'll remove a node from the frontier.

So right now at the beginning, the frontier just contains one node representing the initial state. But over time, the frontier might grow. It might contain multiple states. And so here we're just going to remove a single node from that frontier.
Step4) Loop: Check if the Removed Node is the Goal Node (Solution Found)
If that node happens to be a goal, then we found a solution. So we remove a node from the frontier and ask ourselves, is this the goal?

And we do that by applying the goal test that we talked about earlier, asking if we're at the destination or asking if all the numbers of the 15 puzzle happen to be in order.
So if the node contains the goal, we found a solution. Great. We're done.
Step5) Loop: If Solution not Found, add neighbor Nodes to the Frontier (Expand the Node)
And otherwise, what we'll need to do is we'll need to expand the node.
And this is a term in artificial intelligence. To "expand the node" just means to look at all of the neighbors of that node.
In other words, consider all of the possible actions that I could take from the state that this node is representing and what nodes could I get to from there.
We're going to take all of those nodes, the next nodes that I can get to from this current one I'm looking at, and add those to the frontier. And then we'll repeat this process.

B.5) Strategy into Practice - try to solve a Search Problem (Example) 🔎🧪
Summary:
So at a very high level, the idea is we start with a frontier that contains the initial state. And we're constantly removing a node from the frontier, looking at where we can get to next, and adding those nodes to the frontier, repeating this process over and over until either we remove a node from the frontier and it contains a goal, meaning we've solved the problem. Or we run into a situation where the frontier is empty, at which point we're left with no solution.

So let's actually try and take the pseudocode, put it into practice by taking a look at an example of a sample search problem.
So right here I have a sample graph. A is connected to B via this action, B is connected to node C and D, C is connected to D, E is connected to F.

And what I'd like to do is have my AI find a path from A to E.
We want to get from this initial state to this goal state.
So we will follow the steps and see if we can find a solution.
We start with A, so the frontier is not empty, let's move on...

We pick A to be removed from the Frontier (we only had one choice), this is not the Goal, so we move on...

We add B to the Frontier, Frontier is not empty, let's move on...

We can only remove B from the Frontier, this is not the Goal, so we move on...

We add the next nodes to the Frontier,

We start again, Frontier is not empty, so we remove one node, for example Node C,

Node C is not the Goal, so we Add the Next Nodes (Node E),

Frontier is not empty, so we pick a Node to be removed, for example Node E,

Now we check, is Node E the Goal Node? Yes it is! we found the Solution.

So this is the general idea, the general approach of this search algorithm, to follow these steps constantly removing nodes from the frontier until we're able to find a solution.
B.5.1) How our Strategy Could Fail
So the next question you might reasonably ask is, what could go wrong here? What are the potential problems with an approach like this?
And here's one example of a problem that could arise from this sort of approach.
Imagine this same graph, same as before, with one change. The change being, now, instead of just an arrow from A to B, we also have an arrow from B to A, meaning we can go in both directions.

And this is true in something like the 15 puzzle where when I slide a tile to the right, I could then slide a tile to the left to get back to the original position.

And that's true in many search problems. What's going to happen if I try to apply the same approach now?
B.5.1.1) Example: Failed Strategy when Nodes are Bidirectional (in need of memory)
Well, I'll begin with A, same as before.

And I'll remove A from the frontier. And then I'll consider where I can get to from A.
And after A, the only place I can get choice B so B goes into the frontier.

Then I'll say, all right. Let's take a look at B. That's the only thing left in the frontier. Where can I get to from B? Before it was just C and D, but now because of that reverse arrow, I can get to A or C or D. So all three A, C, and D. All of those now go into the frontier.

And now I remove one from the frontier, and, you know, maybe I'm unlucky and maybe I pick A.
And now I'm looking at A again.

And I consider where can I get to from A. And from A, well I can get to B.

And now we start to see the problem, that if I'm not careful, I go from A to B and then back to A and then to B again.

And I could be going in this infinite loop where I never make any progress because I'm constantly just going back and forth between two states that I've already seen.
So what is the solution to this?
We need some way to deal with this problem. And the way that we can deal with this problem is by somehow keeping track of what we've already explored.

And the logic is going to be:
- if we've already explored the state, there's no reason to go back to it. Once we've explored a state, don't go back to it, don't bother adding it to the frontier. There's no need to.
B.6) Revised Strategy to Solve the Search Problem (implementing Explored Nodes memory 🧠🗺️)
So here is going to be our revised approach, a better way to approach this sort of search problem.
And it's going to look very similar just with a couple of modifications.
Step 1, 2) Initial State and Empty Explored Set
We'll start with a frontier that contains the initial state. Same as before.
But now we'll start with another data structure, which would just be a set of nodes that we've already explored. So what are the states we've explored? Initially, it's empty.

Step 3) Loop: Check "no solution" condition
And now we repeat. If the frontier is empty, no solution. Same as before.
Step 4, 5, 6) Loop: Remove node, check for Goal and Store in Explore Set
We remove a node from the frontier, we check to see if it's a goal state, return the solution.
But now, what we're going to do is we're going to add the node to the explored state.

So if it happens to be the case that we remove a node from the frontier and it's not the goal, we'll add it to the explored set so that we know we've already explored it. We don't need to go back to it again if it happens to come up later.
Step 7) Loop: Expand the Node (add Nodes to the Frontier)
And then the final step, we expand the node and we add the resulting nodes to the frontier.

Important: But before we just always added the resulting nodes to the frontier, we're going to be a little cleverer about it this time. We're only going to add the nodes to the frontier if they aren't already in the frontier and if they aren't already in the explored set. So we'll check both the frontier and the explored set, make sure that the node isn't already in one of those two.
Summary: Revised Approach - Graph Search vs Tree Search
Summary: We are now implementing [[Graph Search]] in our Revised Approach

And so that revised approach is ultimately what's going to help make sure that we don't go back and forth between two nodes.
To solve search problems, we often represent the state space as a graph, where each node is a state and each edge between nodes represents an action. The AI's task is to find a path through this graph from the initial state to the goal state.
We can break down search methods into two major types: [[graph search]] and [[tree search]].
- [[Graph Search]]: Keeps track of previously visited states to avoid revisiting them.
- [[Tree Search]]: Explores new paths without considering whether a state has already been visited.
The key difference lies in efficiency. Graph search is more efficient in preventing repeated exploration of the same states.
Note: So, the difference between tree search and graph search is not that tree search works on trees while graph search works on graphs! Both can work on trees or graphs (but, given that graphs are a generalization of trees, we can simply say that both work on graphs, either trees or not) and both produce a tree!
Note: The Importance of the Frontier Data Structure - How to remove Nodes from a "Stack" Frontier
Now the one point that I've kind of glossed over here so far is this step "removing a node from the frontier".

Before I just chose arbitrarily, like let's just remove a node and that's it.
But it turns out it's actually quite important how we decide to structure our frontier, how we add them, and how we remove our nodes.
The frontier is a data structure. And we need to make a choice about in what order are we going to be removing elements? And one of the simplest [[data structures]] for adding and removing elements is something called a [[stack]].
And a [[stack]] is a [[data structure]] that is a last in, first out data type.

Which means the last thing that I add to the frontier is going to be the first thing that I remove from the frontier.
So the most recent thing to go into the stack, or the frontier in this case, is going to be the node that I explore.
B.7) Strategy into Practice - try to solve a Search Problem (Example: Stack Frontier and Explored Set) - DFS 🔎🧪
So let's see what happens if I apply this stack based approach

to something like this problem, finding a path from A to E. What's going to happen?

Well, again we'll start with A.

And then, notice this time, we've added A to the explored set.
A is something we've now explored, we have this data structure that's keeping track.

We then say from A we can get to B.

From B what can we do? Well from B, we can explore B and get to both C and D. So we added FIRST "C" and "THEN" D.

So now when we explore a node, we're going to treat the frontier as a stack, last in, first out.
D was the last one to come in so we'll go ahead and explore that next.

And say, all right, where can we get to from D? Well we can get to F. And so, we'll put F into the frontier.

And now because the frontier is a stack, F is the most recent thing that's gone in the stack. So F is what we'll explore next.

We'll explore F and say, all right. Where can we get you from F? Well, we can't get anywhere so nothing gets added to the frontier.
So now what was the new most recent thing added to the frontier? Well it's now C, the only thing left in the frontier. We'll explore that

from which we can say, all right, from C we can get to E.
So E goes into the frontier.

And then we say, all right. Let's look at E and E is now the solution. And now we've solved the problem.
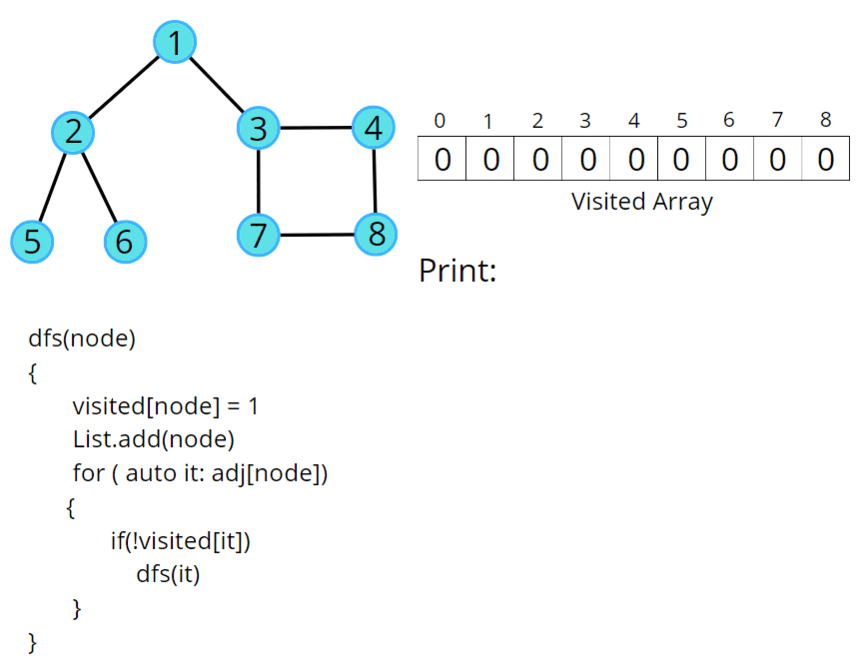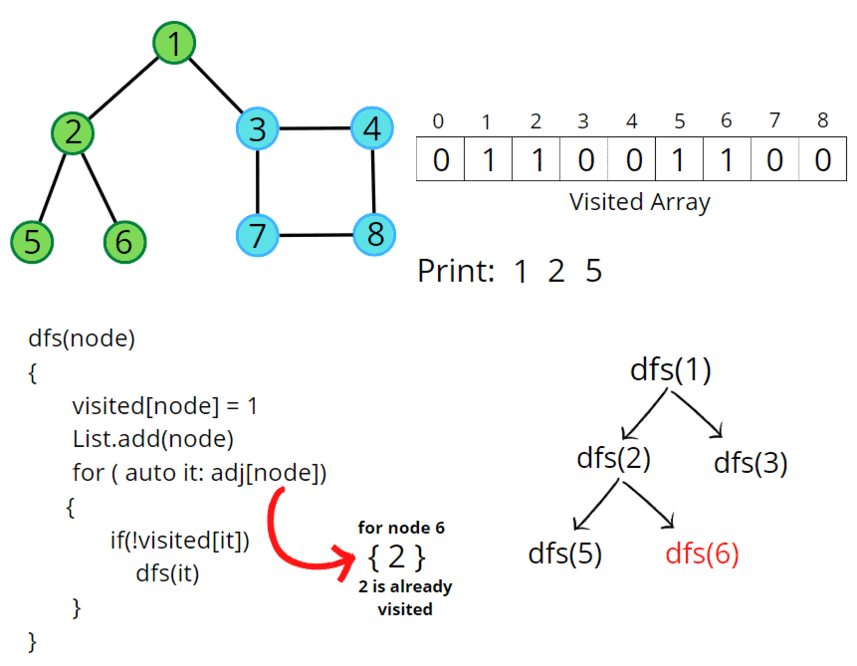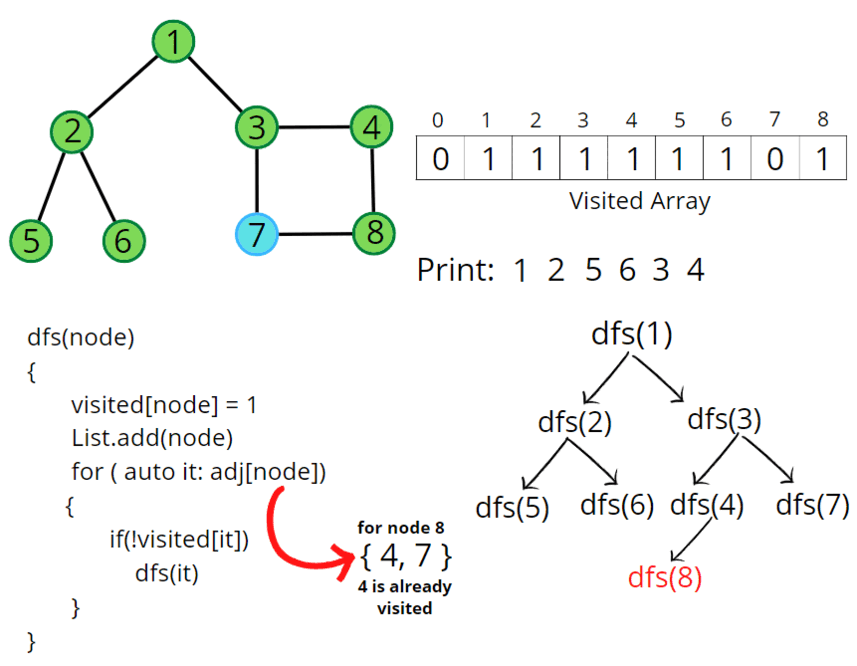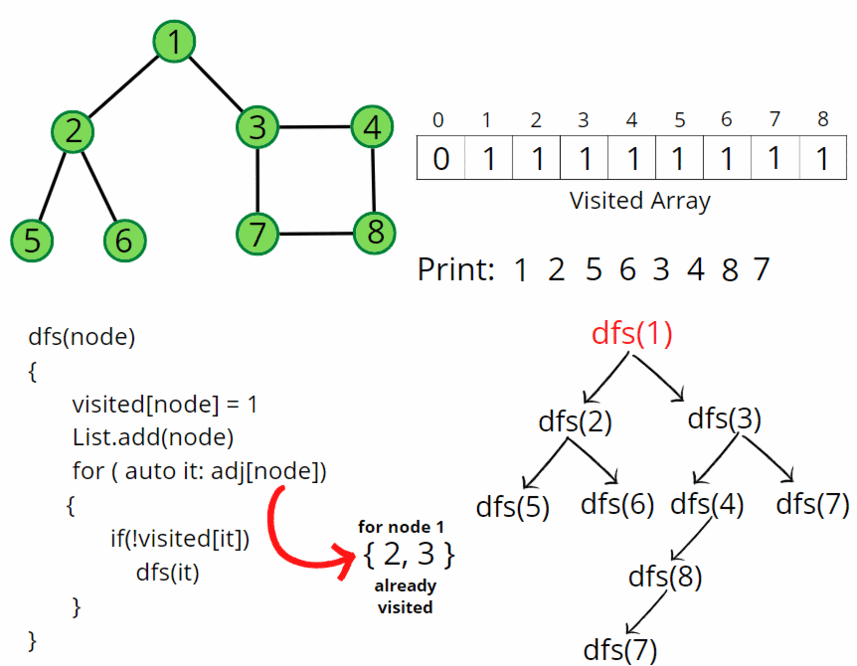
B.7.1) Intro to Depth-First Search (using the Stack Frontier) 🤖
So when we treat the frontier like a [[stack]], a last in, first out [[data structure]],
that's the result we get. We go from A to B to D to F, and then we sort of backed up and went down to C and then E.

And it's important to get a visual sense for how this algorithm is working. We went very deep in this search tree, so to speak, all the way until the bottom where we hit a dead end.
And then we effectively backed up and explored this other route that we didn't try before.
And it's this going very deep in the search tree idea, this way the algorithm ends up working when we use a stack, that we call this version of the algorithm Depth-First Search (DFS).

Depth-First Search (DFS) is the search algorithm where we always explore the deepest node in the frontier. We keep going deeper and deeper through our search tree. And then if we hit a dead end, we back up and we try something else instead.
Note: DFS works well for some problems but is not guaranteed to find the shortest solution, as it may get "stuck" exploring one long path before backtracking to a shorter one.
But Depth-First Search (DFS) is just one of the possible search options that we could use....
B.7.2) Intro to Breadth-First Search (using the Queue Frontier) 🤖
It turns out that there is another algorithm called Breadth-First Search (BFS), which behaves very similarly to Depth-First Search (DFS) with one difference.
Instead of always exploring the deepest node in the search tree the way the Depth-First Search (DFS) does, Breadth-First Search (BFS) is always going to explore the shallowest node in the frontier.

So what does that mean? Well, it means that instead of using a Depth-First Search (DFS) , used where the most recent item added to the frontier is the one we'll explore next, in Breadth-First Search (BFS), will instead use a [[queue]]
where a [[queue]] is a first in, first out data type, where the very first thing we add to the frontier is the first one we'll explore.

And they effectively form a line or a queue, where the earlier you arrive in the frontier, the earlier you get explored.
B.8) Strategy into Practice - try to solve a Search Problem (Example: Queue Frontier and Explored Set) - BFS 🔎🧪
So what would that mean for the same exact problem finding a path from A to E?

Well we start with A, same as before.

Then we'll go ahead and have explored A,

and say, where can we get to from A? Well, from A we can get to B. Same as before.

From B, we can get to C and D, so C and D get added to the frontier (same as before)

This time, though, we added C to the frontier before D so we'll explore C first.

So C gets explored. And from C, where can we get to? Well, we can get to E.
So E gets added to the frontier. But because D was explored before E, we'll look at D next.

So we'll explore D and say,

where can we get to from D? We can get to F.

And only then will we say, all right. Now we can get to E. SOLVED

B.8.1) Comparing Breadth-First Search (BFS) vs Depth-First Search (DFS)
And so what Breadth-First Search (BFS), did is we started here, we looked at both C and D, and then we looked at E. Effectively we're looking at things one away from the initial state, then two away from the initial state. And only then, things that are three away from the initial state.

Unlike Depth-First Search (DFS) , which just went as deep as possible into the search tree until it hit a dead end and then, ultimately, had to back up.
Conclusion: Breadth-First Search (BFS), in contrast to DFS, explores all possible nodes at one depth level before moving on to the next. It uses a queue to store the nodes to explore, which guarantees that the shortest solution is found, assuming each action has the same cost.
Note: However, BFS can be slow for problems with large state spaces, as it may need to explore a huge number of nodes before finding the goal.
So these now are two different search algorithms that we could apply in order to try and solve a problem.
__________________________________________________________
C) Solving a Maze with our Search Algorithms (DFS and BFS) 🔀
And let's take a look at how these would actually work in practice with something like maze solving, for example. So here's an example of a maze.

These empty cells represent places where our agent can move.

These darkened gray/blue cells and represent walls that the agent can't pass through.

And, ultimately, our agent, our AI, is going to try to find a way to get from position A to position B via some sequence of actions, where those actions are left, right, up, and down.

C.1) Solving a Maze with Depth-First Search (DFS)
What will Depth-First Search (DFS) do in this case? Well Depth-First Search (DFS) will just follow one path.

If it reaches a fork in the road where it has multiple different options, Depth-First Search (DFS) is just, in this case, going to choose one. There isn't a real preference. But it's going to keep following one until it hits a dead end.

And when it hits a dead end, Depth-First Search (DFS) effectively goes back to the last decision point.

and tries the other path. Fully exhausting this entire path

and when it realizes that, OK, the goal is not here, then it turns its attention to this path.

It goes as deep as possible. When it hits a dead end, it backs up and then tries this other path,

keeps going as deep as possible down one particular path, and when it realizes that that's a dead end, then it'll back up.

And then ultimately find its way to the goal.

And maybe you got lucky and maybe you made a different choice earlier on, but ultimately this is how Depth-First Search (DFS) is going to work. It's going to keep following until it hits a dead end. And when it hits a dead end, it backs up and looks for a different solution.
C.1.1) Reviewing the Depth-First Search (DFS) Solution
And so one thing you might reasonably ask is,
- Is this algorithm always going to work? Will it always actually find a way to get from the initial state to the goal?

And it turns out that as long as our maze is finite, as long as they're that finitely many spaces where we can travel, then yes. Depth-First Search (DFS) is going to find a solution because eventually it will just explore everything.

If the maze happens to be infinite and there's an infinite state space, which does exist in certain types of problems, then it's a slightly different story....

But as long as our maze has finitely many squares, we're going to find a solution.
The next question, though, that we want to ask is,
- Is it going to be a good solution? Is it the optimal solution that we can find?

And the answer is "not necessarily".
C.1.2) Example: Depth-First Search (DFS) when "random" can make you look "dumb"
And let's take a look at an example of that. In this maze, for example, we're again trying to find our way from A to B.

And you notice here there are multiple possible solutions.
We could go this way,

or we could go up in order to make our way from A to B.

Now if we're lucky, depth first search will choose the shortest path and get to B.
But there's no reason, necessarily, why depth first search would choose between going up or going to the right. It's sort of an arbitrary decision point because both are going to be added to the frontier.
And ultimately, if we get unlucky, depth first search might choose to explore this path first because it's just a random choice at this point.
It will explore, explore, explore, and it'll eventually find the goal, this particular path, when in actuality there was a better path.

There was a more optimal solution that used fewer steps, assuming we're measuring the cost of a solution based on the number of steps that we need to take.
So Depth-First Search (DFS) if we're unlucky, might end up not finding the best solution when a better solution is available.
C.2) Solving a Maze with Breadth-First Search (BFS)
How does Breadth-First Search (BFS), compare?
How would it work in this particular situation?

Well the algorithm is going to look very different visually in terms of how Breadth-First Search (BFS) explores.
Because Breadth-First Search (BFS) looks at shallower nodes first, the idea is going to be Breadth-First Search (BFS) will first look at all of the nodes that are one away from the initial state.

Then it will explore nodes that are two away, looking at that state and that state, for example.

Then it will explore nodes that are three away, this state and that state.

Whereas Depth-First Search (DFS) just picked one path and kept following it,

Breadth-First Search (BFS) on the other hand, is taking the option of exploring all of the possible paths kind of at the same time, bouncing back between them, looking deeper and deeper at each one, but making sure to explore the shallower ones or the ones that are closer to the initial state earlier.

C.2.1) Reviewing the Breadth-First Search (DFS) Solution
So we'll keep following this pattern, looking at things that are four away,

looking at things that are five away, looking at things that are six away, until eventually we make our way to the goal.

And in this case, it's true we had to explore some states that ultimately didn't lead us anywhere....
But the path that we found to the goal was the optimal path. This is the shortest way that we could get to the goal.
C.2.2) Example: Trying to Solve a Larger Maze wih Breadth-First Search (BFS)
And so, what might happen then in a larger maze? Well let's take a look at something like this and how breadth first search is going to behave.

Well, Breadth-First Search (BFS), again, will just keep following the states until it receives a decision point. It could go either left or right.

And while Breadth-First Search (BFS) on the other hand, will explore both. It'll say, look at this node, then this node,

so on and so forth.

And when it hits a decision point here,

rather than pick one left or two right and explore that path, it will again explore both alternating between them, going deeper and deeper.
Will explore here,

and then start a new branch to explore here,

and here,

it will split again

and go here,

and here,

and then keep going, and slowly make our way,

you can visually see further and further out. Once we get to this decision point, we'll explore both up and down,

and keep going,

and going,

and going,

until, ultimately, we make our way to the goal.

C.2.2.1) Breadth-First Search (BFS) vs Depth-First Search (DFS) (speed and memory comparison)
And what you'll notice is, yes, Breadth-First Search (BFS) did find our way from A to B by following this particular path.

But it needed to explore a lot of states in order to do so. And so we see some trade here between DFS and BFS.
That in [[Depth-First Search (DFS)]] there may be some cases where there is some memory savings,
as compared to a Breadth-First Search (BFS) approach where Breadth-First Search (BFS) , in this case, had to explore a lot of states. But maybe that won't always be the case.
C.3) Writing Code to Solve a Maze with DFS and BFS in Python 🔀👨💻
So now let's actually turn our attention to some code. And look at the code that we could actually write in order to implement something like Breadth-First Search (BFS) in the context of solving a maze, for example.
So I'll go ahead and go into my terminal.
It is recommended to have a fresh memory about [[Programación Orientada a Objetos]]
Read More Here: [[Introducción a la POO por EDteam]]
And what I have here inside of maze.py is an implementation of this same idea of maze solving.

C.3.1) class Node()
I've defined a class called Node() that in this case is keeping track of:
- the current state,
- the parent, in other words the state before the current state,
- and the action.

Note: In this case, we're not keeping track of the path cost because we can calculate the cost of the path at the end after we found our way from the initial state to the goal.
Copy Python Code:
class Node():
def __init__(self, state, parent, action):
self.state = state
self.parent = parent
self.action = action
C.3.2) class StackFrontier()
In addition to this, I've defined a class called a StackFrontier().

Note: If unfamiliar with a class, a class is a way for me to define a way to generate objects in Python.

It refers to an idea of object oriented programming where the idea here is that I would like to create an object that is able to store all of my Frontier Data. And I would like to have functions, otherwise known as methods on that object, that I can use to manipulate the object.

And so what's going on here, if unfamiliar with the syntax, is I have a function that initially creates a frontier that I'm going to represent using a list. And initially my frontier is represented by the empty list. There's nothing in my frontier to begin with.

I have an add function that adds something to the frontier, as by appending it to the end of the list.

I have a function that checks if the frontier contains a particular state.

I have an empty function that checks if the frontier is empty. If the frontier is empty, that just means the length of the frontier is zero.

And then I have a function for removing something from the frontier.
Note: I can't remove something from the frontier if the frontier is empty. So I check for that first.

But otherwise, if the frontier isn't empty, recall that I'm implementing this frontier as a stack, a last in, first out data structure.
Which means the last thing I add to the frontier, in other words, the last thing in the list, is the item that I should remove from this frontier.
So what you'll see here is I have removed the last item of a list. And if you index into a Python list with negative one, that gets you the last item in the list. Since zero is the first item, negative one kind of wraps around and gets you to the last item in the list.

Then we update the frontier. And then we return the node as a result.

Summary: So this class here effectively implements the idea of a [[frontier]]. It gives me a way to add something to a frontier and a way to remove something from the frontier as a [[stack]].
Copy Python Code:
class StackFrontier():
def __init__(self):
self.frontier = []
def add(self, node):
self.frontier.append(node)
def contains_state(self, state):
return any(node.state == state for node in self.frontier)
def empty(self):
return len(self.frontier) == 0
def remove(self):
if self.empty():
raise Exception("empty frontier")
else:
node = self.frontier[-1]
self.frontier = self.frontier[:-1]
return node
C.3.3) class QueueFrontier(StackFrontier)
I've also, implemented an alternative version of the same thing called a QueueFrontier().

Which, in parentheses you'll see here, it inherits from a Stack Frontier, meaning it's going to do all the same things that the StackFrontier() did, except the way we remove a node from the frontier is going to be slightly different.
Instead of removing from the end of the list the way we would in a stack, we're instead going to remove from the beginning of the list.

self.frontier[0] will get me the first node in the frontier, the first one that was added.
And that is going to be the one that we return in the case of a [[Queue]].
Copy Python Code:
class QueueFrontier(StackFrontier):
def remove(self):
if self.empty():
raise Exception("empty frontier")
else:
node = self.frontier[0]
self.frontier = self.frontier[1:]
return node
C.3.4) class Maze()
Then I have a definition of a class called Maze().

This is going to handle the process of taking a sequence, a maze like text file, and figuring out how to solve it.
So we'll take as input a text file that looks something like this, for example,

where we see hash marks that are here representing walls and I have the character A representing the starting position, and the character B representing the ending position.
C.3.4.1) Part 1: Parsing the Text File, Finding Start and Goal, Neighbors function
And you can take a look at the code for parsing this text file right now. That's the less interesting part....
__init__)The constructor initializes the maze by reading from a file, validating its layout, and setting up internal data structures.
Constructor Code:
def __init__(self, filename):
# Read file and set height and width of maze
with open(filename) as f:
contents = f.read()
# Validate start and goal
if contents.count("A") != 1:
raise Exception("maze must have exactly one start point")
if contents.count("B") != 1:
raise Exception("maze must have exactly one goal")
# Determine height and width of maze
contents = contents.splitlines()
self.height = len(contents)
self.width = max(len(line) for line in contents)
Code Explanation:
- Reads the maze layout from a file.
- Checks that there is exactly one start point (
"A") and one goal point ("B"). If not, it raises an exception. - Determines the
height(number of lines) andwidth(longest line) of the maze.
This part processes the maze content to identify walls and open spaces, and stores the coordinates of the start and goal points.
Tracking Code:
# Keep track of walls
self.walls = []
for i in range(self.height):
row = []
for j in range(self.width):
try:
if contents[i][j] == "A":
self.start = (i, j)
row.append(False)
elif contents[i][j] == "B":
self.goal = (i, j)
row.append(False)
elif contents[i][j] == " ":
row.append(False)
else:
row.append(True)
except IndexError:
row.append(False)
self.walls.append(row)
self.solution = None
Code Explanation:
- Creates a 2D list (
self.walls) to keep track of walls and open spaces.Trueindicates a wall,Falsemeans an open space.
- Identifies the coordinates of the start (
self.start) and goal (self.goal) positions. - If a character is
"A", it stores the position as the start point and marks the cell as open (False). - If it's
"B", it stores it as the goal point and marks it as open (False). - All other characters are treated as walls unless explicitly defined as open (
" ").
print)This method prints the maze to the console, showing walls, start and goal positions, and a possible solution path.
Printing Code:
def print(self):
solution = self.solution[1] if self.solution is not None else None
print()
for i, row in enumerate(self.walls):
for j, col in enumerate(row):
if col:
print("█", end="")
elif (i, j) == self.start:
print("A", end="")
elif (i, j) == self.goal:
print("B", end="")
elif solution is not None and (i, j) in solution:
print("*", end="")
else:
print(" ", end="")
print()
print()
Code Explanation:
- Iterates over the maze and prints characters to represent different elements:
█for wallsAfor the start pointBfor the goal point*for the solution path (if available)" "for open spaces
neighbors)This method calculates the possible moves from a given position in the maze, considering the typical directions ("up", "down", "left", "right").
Neighbor Code:
def neighbors(self, state):
row, col = state
# All possible actions
candidates = [
("up", (row - 1, col)),
("down", (row + 1, col)),
("left", (row, col - 1)),
("right", (row, col + 1))
]
# Ensure actions are valid
result = []
for action, (r, c) in candidates:
try:
if not self.walls[r][c]:
result.append((action, (r, c)))
except IndexError:
continue
return result
Code Explanation:
- Takes a position (
state) as input and tries to find all valid neighboring positions that can be moved to. - Defines potential moves (up, down, left, right) by calculating new coordinates.
- Checks if the new coordinates are open spaces and not walls. If they are valid, they are added to the result list.
- Handles cases where coordinates might be out of bounds by catching
IndexErrorexceptions.
The Maze class provides essential functions to:
- Read and validate a maze layout from a file.
- Identify and store key elements like the start, goal, and walls.
- Print the maze for easy visualization, including paths if solutions are provided.
- Determine possible movements (neighbors) for navigating through the maze, which could be useful for solving it using various algorithms.
C.3.4.2) Part 2: creating a solve function <---- IMPORTANT 💡✅
The more interesting part is this solve function here,

where the solve function is going to figure out how to actually get from point A to point B.
And here we see an implementation of the exact same idea we saw from a moment ago.
We're going to keep track of how many states we've explored, just so we can report that data later.

But I start with a node that represents just the start state.
And I start with a frontier that in this case is a stack frontier.

And given that I'm treating my frontier as a stack, the algorithm I'm using here is [[Depth-First Search (DFS)]].
Next, we initialize an explored set that initially is empty. There's nothing we've explored so far.

And now here's our loop, that notion of repeating something again and again.

First, we check if the frontier is empty (by calling that empty function that we saw the implementation previously). And if the frontier is indeed empty, we'll go ahead and raise an exception, or a Python error, to say, Sorry there is no solution to this problem. Otherwise, we'll go ahead,

next, we remove a node from the frontier, as by calling frontier.remove

and update the number of states we've explored. Because now we've explored one additional state so we say self.num_explored += 1, adding one to the number of states we've explored.
Once we remove a node from the frontier, recall that the next step is to see whether or not it's the goal, the goal test.
And in the case of the maze, the goal is pretty easy. I check to see whether the state of the node is equal to the goal.

And if it is the goal, then what I want to do is backtrack my way towards figuring out what actions I took in order to get to this goal. And how do I do that?
We'll recall that every node stores its parent-- the node that came before it that we used to get to this node-- and also the action used in order to get there.
Remember...

So I can create this loop where I'm constantly just looking at the parent of every node and keeping track, for all of the parents, what action I took to get from the parent to this.

So this loop is going to keep repeating this process of looking through all of the parent nodes until we get back to the initial state, which has no parent, where node.parent is going to be equal to None.
As I do so, I'm going to be building up the list of all of the actions that I'm following and the list of all of the cells that are part of the solution.

Finally, I'll reverse them because when I build it up, I was going from the goal back to the initial state. So when I'm building the sequence of actions from the goal to the initial state, I want to reverse them in order to get the sequence of actions from the initial state to the goal.
And that is, ultimately, going to be the solution. So all of that happens if the current state is equal to the goal. Otherwise if it's not the goal...
then I'll go ahead and add this state to the explored set to say, I've explored this state now.
No need to go back to it if I come across it in the future.

And then, this logic here implements the idea of adding neighbors to the frontier.

I'm saying, look at all of my neighbors based on my node.state.
And for each of those neighbors, I'm going to check, is the state already in the frontier? AND Is the state already in the explored set?
if it's not in either of those, then I'll go ahead and add this new child node-- this new node-- to the frontier.
Conclusion:
So there's a fair amount of syntax here, but the key here is not to understand all the nuances of the syntax, though feel free to take a closer look at this file on your own to get a sense for how it is working. But the key is to see how this is an implementation of the same pseudocode, the same idea that we were describing a moment ago on the screen when we were looking at the steps that we might follow in order to solve this kind of search problem.
Copy Code:
def solve(self):
"""Finds a solution to maze, if one exists."""
# Keep track of number of states explored
self.num_explored = 0
# Initialize frontier to just the starting position
start = Node(state=self.start, parent=None, action=None)
frontier = StackFrontier()
frontier.add(start)
# Initialize an empty explored set
self.explored = set()
# Keep looping until solution found
while True:
# If nothing left in frontier, then no path
if frontier.empty():
raise Exception("no solution")
# Choose a node from the frontier
node = frontier.remove()
self.num_explored += 1
# If node is the goal, then we have a solution
if node.state == self.goal:
actions = []
cells = []
# Follow parent nodes to find solution
while node.parent is not None:
actions.append(node.action)
cells.append(node.state)
node = node.parent
actions.reverse()
cells.reverse()
self.solution = (actions, cells)
return
# Mark node as explored
self.explored.add(node.state)
# Add neighbors to frontier
for action, state in self.neighbors(node.state):
if not frontier.contains_state(state) and state not in self.explored:
child = Node(state=state, parent=node, action=action)
frontier.add(child)
C.3.5) Testing the code: running maze.py using Depth-First Search (DFS) 🔎🧪
So now let's actually see this in action!
Note: The Python code is mostly complete, but it is missing the entry point (if __name__ == "__main__":) to run it as a script when executed from the command line.
Here’s what you need to add to be able to run it properly:
Code:
`if __name__ == "__main__":
if len(sys.argv) != 2:
sys.exit("Usage: python maze.py filename")
filename = sys.argv[1]
maze = Maze(filename)
maze.solve()
maze.print()`
This part of the code does the following:
- Checks if there is exactly one command-line argument provided (which should be the filename).
- Creates a
Mazeobject using the provided filename. - Calls
solve()to find a solution to the maze. - Calls
print()to display the maze with the solution, if found.
With this addition, you should be able to run the code with the command python maze.py maze1.txt.
Copy Full Code: maze.py
import sys
class Node:
def __init__(self, state, parent, action):
self.state = state
self.parent = parent
self.action = action
class StackFrontier:
def __init__(self):
self.frontier = []
def add(self, node):
self.frontier.append(node)
def contains_state(self, state):
return any(node.state == state for node in self.frontier)
def empty(self):
return len(self.frontier) == 0
def remove(self):
if self.empty():
raise Exception("empty frontier")
else:
node = self.frontier[-1]
self.frontier = self.frontier[:-1]
return node
class QueueFrontier(StackFrontier):
def remove(self):
if self.empty():
raise Exception("empty frontier")
else:
node = self.frontier[0]
self.frontier = self.frontier[1:]
return node
class Maze:
def __init__(self, filename):
# Read file and set height and width of maze
with open(filename) as f:
contents = f.read()
# Validate start and goal
if contents.count("A") != 1:
raise Exception("maze must have exactly one start point")
if contents.count("B") != 1:
raise Exception("maze must have exactly one goal")
# Determine height and width of maze
contents = contents.splitlines()
self.height = len(contents)
self.width = max(len(line) for line in contents)
# Keep track of walls
self.walls = []
for i in range(self.height):
row = []
for j in range(self.width):
try:
if contents[i][j] == "A":
self.start = (i, j)
row.append(False)
elif contents[i][j] == "B":
self.goal = (i, j)
row.append(False)
elif contents[i][j] == " ":
row.append(False)
else:
row.append(True)
except IndexError:
row.append(False)
self.walls.append(row)
self.solution = None
def print(self):
solution = self.solution[1] if self.solution is not None else None
print()
for i, row in enumerate(self.walls):
for j, col in enumerate(row):
if col:
print("#", end="")
elif (i, j) == self.start:
print("A", end="")
elif (i, j) == self.goal:
print("B", end="")
elif solution is not None and (i, j) in solution:
print("*", end="")
else:
print(" ", end="")
print()
print()
def neighbors(self, state):
row, col = state
# All possible actions
candidates = [
("up", (row - 1, col)),
("down", (row + 1, col)),
("left", (row, col - 1)),
("right", (row, col + 1))
]
# Ensure actions are valid
result = []
for action, (r, c) in candidates:
try:
if not self.walls[r][c]:
result.append((action, (r, c)))
except IndexError:
continue
return result
def solve(self):
"""Finds a solution to maze, if one exists."""
# Keep track of number of states explored
self.num_explored = 0
# Initialize frontier to just the starting position
start = Node(state=self.start, parent=None, action=None)
frontier = StackFrontier()
frontier.add(start)
# Initialize an empty explored set
self.explored = set()
# Keep looping until solution found
while True:
# If nothing left in frontier, then no path
if frontier.empty():
raise Exception("no solution")
# Choose a node from the frontier
node = frontier.remove()
self.num_explored += 1
# If node is the goal, then we have a solution
if node.state == self.goal:
actions = []
cells = []
# Follow parent nodes to find solution
while node.parent is not None:
actions.append(node.action)
cells.append(node.state)
node = node.parent
actions.reverse()
cells.reverse()
self.solution = (actions, cells)
return
# Mark node as explored
self.explored.add(node.state)
# Add neighbors to frontier
for action, state in self.neighbors(node.state):
if not frontier.contains_state(state) and state not in self.explored:
child = Node(state=state, parent=node, action=action)
frontier.add(child)
if __name__ == "__main__":
if len(sys.argv) != 2:
sys.exit("Usage: python maze.py filename")
filename = sys.argv[1]
maze = Maze(filename)
maze.solve()
maze.print()
C.3.5.1) Testing a simple maze with DFS
I'll go ahead and run maze.py on maze1.txt, for example.

And we have a printout of what the maze initially looked like.

And then here, down below, is after we've solved it.

We had to explore 11 states in order to do it, and we found a path from A to B.
And in this program, I just happened to generate a graphical representation of this, as well-- so I can open up maze.png,

which is generated by this program that shows you where,
- in the darker color where the wall is.
- Red is the initial state,
- green is the goal,
- and yellow is the path that was followed.

We found a path from the initial state to the goal.
C.3.5.2) Testing a complex maze with DFS
But now let's take a look at a more sophisticated maze to see what might happen instead.
Let's look now at maze2.txt, where now here we have a much larger maze.

Again, we're trying to find our way from point A to point B, but now you'll imagine that [[Depth-First Search (DFS)]] might not be so lucky.
It might not get the goal on the first try. It might have to follow one path then backtrack and explore something else a little bit later.
So let's try this.
Run pythonmaze.py of maze2.txt

And now [[Depth-First Search (DFS)]] is able to find a solution.
Here, as indicated by the stars, is a way to get from A to B.

And we can represent this visually by opening up this maze.
Here's what that maze looks like. And highlighted in yellow, is the path that was found from the initial state to the goal

But how many states do we have to explore before we found that path?
Well, recall that, in my program, I was keeping track of the number of states that we've explored so far. In order to solve this problem, we had to explore 399 different states.

And in fact, if I make one small modification to the program and tell the program at the end when we output this image, I added an argument called "show explored".

And if I set "show explored" equal to true and rerun this program pythonmaze.py by running it on maze2.txt, and then I open the maze, what you'll see here is, highlighted in red, are all of the states that had to be explored to get from the initial state to the goal.

[[Depth-First Search (DFS)]], didn't find its way to the goal right away.
It made several choices to first explore other directions. And when it explored a direction, it had to follow every conceivable path, all the way to the very end, in order to realize that it is in a dead end.
Then, the program needed to backtrack. After going into a wrong direction. It can get lucky sometimes, but not always.
So all in all, [[Depth-First Search (DFS)]] here really is not performing optimally, or probably exploring more states than it needs to.
It finds an optimal solution, the best path to the goal, but the number of states needed to explore in order to do so, the number of steps I had to take, that was much higher.
C.3.6) Testing the code: running maze.py using Breadth-First Search (BFS) 🔎🧪
C.3.6.1) Testing the same complex maze but now with BFS
So let's compare. How would Breadth-First Search (BFS), do on this exact same maze instead?
And in order to do so, it's a very easy change.
The algorithm for DFS and BFS is identical with the exception of what data structure we use to represent the [[frontier]].
That in DFS I used a stack frontier-- last in, first out--

whereas in BFS, I'm going to use a queue frontier-- first in, first out--

So I'll go back to the terminal, rerun this program on the same maze,

I get a solution,

and now you'll see that the number of states we had to explore was only 77,

as compared to almost 400 when we used [[Depth-First Search (DFS)]]
And we can see exactly why. We can see what happened if we open up maze.png now and take a look.

Again, yellow highlight is the solution that Breadth-First Search (BFS) found, which, incidentally, is the same solution that [[Depth-First Search (DFS)]] found.
They're both finding the best solution, but notice all the white unexplored cells.
There was much fewer states that needed to be explored in order to make our way to the goal because Breadth-First Search (BFS) operates a little more shallowly.
It's exploring things that are close to the initial state without exploring things that are further away. So if the goal is not too far away, then [[Breadth-First Search (BFS)]] can actually behave quite effectively on a maze that looks a little something like this.
C.3.7) Testing a "tricky" maze with both DFS & BFS 🔎🧪
Now, in this case, both BFS and DFS ended up finding the same solution, but that won't always be the case.
And in fact, let's take a look at one more example, for instance, maze3.txt.
In maze3.txt, notice that here there are multiple ways that you could get from A to B.

It's a relatively small maze, but let's look at what happens.
a) Guaranteed Optimal Solution from BFS
If I use [[Breadth-First Search (BFS)]] , to solve maze3.txt, well, then we find a solution.

And if I open up the maze, here's the solution that we found. It is the optimal one.

With just four steps, we can get from the initial state to what the goal happens to be.
b) The Unlucky "Long" Solution from DFS
But what happens if we try to use [[Depth-First Search (DFS)]], instead?
Well, again, I'll go back up to my queue frontier, where queue frontier means that we're using [[Breadth-First Search (BFS)]]. And I'll change it to a stack frontier, which means that now we'll be using [[Depth-First Search (DFS)]],

I'll rerun Pythonmaze.py. And now you'll see that we find a solution, but it is not the optimal solution.

This, instead, is what our algorithm finds. And maybe [[Depth-First Search (DFS)]] would have found this solution. It's possible, but it's not guaranteed.
If we just happen to be unlucky and we choose a bad state, then [[Depth-First Search (DFS)]] might find a longer route to get from the initial state to the goal.
So we do see some trade-offs here where [[Depth-First Search (DFS)]] might not find the optimal solution.
So at that point, it seems like [[Breadth-First Search (BFS)]] is pretty good.
Is that the best we can do, where it's going to find us the optimal solution and we don't have to worry about situations where we might end up finding a longer path to the solution than what actually exists?
c) Breadth-First Search (BFS) vs Depth-First Search (DFS) (speed and memory comparison)
Let's remember this example from [[Breadth-First Search (BFS)]]....
We did find our way from A to B by following this particular path.
But it needed to explore a lot of states in order to do so. And so we see some trade here between DFS and BFS.
That in [[Depth-First Search (DFS)]] there may be some cases where there is some memory savings, as compared to a [[Breadth-First Search (BFS)]] approach
where [[Breadth-First Search (BFS)]] , in this case, had to explore a lot of states. But maybe that won't always be the case.
What ended up happening, is that this algorithm, [[Breadth-First Search (BFS)]], ended up exploring basically the entire graph, having to go through the entire maze in order to find its way from the initial state to the goal state.
What we'd ultimately like is for our algorithm to be a little bit more intelligent.
____________________________________________________________
C.4) Introducing "Human Intuition" to the Maze Problem - making BFS "intelligent" 👀🧠
And now what would it mean for our algorithm to be a little bit more intelligent, in this case?
Well, let's look back to where [[Breadth-First Search (BFS)]] might have been able to make a different decision and consider human intuition in this process, as well.
Like, what might a human do when solving this maze that is different than what [[Breadth-First Search (BFS)]] ultimately chose to do?

Well, the very first decision point that BFS made was right here,
when it made five steps and ended up in a position where it had a fork in the road.
It could either go left or it could go right.
In these initial couple of steps, there was no choice. There was only one action that could be taken from each of those states.

And so the search algorithm did the only thing that any search algorithm could do, which is keep following that state after the next state.
But this decision point is where things get a little bit interesting.
Remember... [[Depth-First Search (DFS)]] , that very first search algorithm we looked at, chose to say, let's pick one path and exhaust that path, see if anything that way has the goal, and if not, then let's try the other way.

[[Breadth-First Search (BFS)]] took the alternative approach of saying,
you know what? Let's explore things that are shallow, close to us first,
- look left and right,
- then back left and back right,
- so on and so forth,
alternating between our options in the hopes of finding something nearby.
But ultimately, what might a human do if confronted with a situation like this:
- go left
- or go right?

Well, a human might visually see that I'm trying to get to state B, which is way up there, and going "right" just feels like it's "closer" to the goal.

Like, it feels like going right should be better than going left because I'm making progress towards getting to that goal.
Now, of course, there are a couple of assumptions that I'm making here.
- I'm making the assumption that we can represent this grid as, like, a two-dimensional grid, where I know the coordinates of everything.
- I know that A is in coordinate 0,0, and B is in some other coordinate pair.
- And I know what coordinate I'm at now, so I can calculate that, yeah, going this way, that is closer to the goal.
And that might be a reasonable assumption for some types of search problems but maybe not in others. But for now, we'll go ahead and assume that-- that I know what my current coordinate pair and I know the coordinate x,y of the goal that I'm trying to get to.

And in this situation, I'd like an algorithm that is a little bit more intelligent and somehow knows that I should be making progress towards the goal, and this is probably the way to do that because, in a maze, moving in the coordinate direction of the goal is usually, though not always, a good thing.
In such a scenario, we distinguish between uninformed and informed search algorithms
-
Uninformed Search: Strategies like DFS and BFS explore available actions without using problem-specific knowledge, leading to less efficient searches.
-
Informed Search: Algorithms like A* and Greedy Best-First Search use heuristics to improve efficiency.
Uninformed search algorithms do not use any domain-specific information to guide their search.
Examples include:
-
Depth-First Search (DFS): Explores as deeply as possible along each branch before backtracking. It does not guarantee the shortest path and can get stuck in deep paths.
-
Breadth-First Search (BFS): Explores all nodes level by level, guaranteeing the shortest solution for unweighted graphs, but can be slow for large problems.
-
Iterative Deepening Search (IDS): A combination of depth-limited and breadth-first approaches, incrementally deepening the search until a solution is found. IDS benefits from the space efficiency of DFS and the completeness of BFS.
Informed search algorithms use problem-specific knowledge to find solutions more efficiently:
Examples include:
-
Greedy Best-First Search: Uses heuristics to guide exploration, but does not guarantee optimality.
-
A*: Combines path cost and heuristics to guarantee optimal solutions, provided the heuristic is admissible and consistent.
-
Bidirectional Search: An informed search technique that runs two simultaneous searches: one forward from the initial state and one backward from the goal state, meeting in the middle. This method reduces time complexity, making it especially useful in large search spaces.
C.4.1) Uninformed Search Algorithms (DFS and BFS)

Uninformed Search Algorithms are algorithms like:
- [[Depth-First Search (DFS)]]
- [[Breadth-First Search (BFS)]]
the two algorithms that we just looked at, which are search strategies that don't use any problem specific knowledge to be able to solve the problem.
DFS and BFS didn't really care about the structure of the maze or anything about the way that a maze is in order to solve the problem. They just look at the actions available and choose from those actions, and it doesn't matter whether if it's a maze or some other problem. The solution, or the way that it tries to solve the problem, is really fundamentally going to be the same.
What we're going to take a look at now is an improvement upon uninformed search.
We're going to take a look at informed search.
C.4.2) Informed Search Algorithms

Informed search are going to be search strategies that use knowledge specific to the problem to be able to better find a solution.
And in the case of a maze, this problem specific knowledge is something like,
- if I'm going to square that is geographically closer to the goal, that is better than being in a square that is geographically further away.
And this is something we can only know by thinking about this problem and reasoning about what knowledge might be helpful for our AI agent to know a little something about.
There are a number of different types of informed search. Specifically, first, we're going to look at a particular type of search algorithm called Greedy Best-First Search (GBFS).
C.4.2.1) Intro to Greedy Best-First Search (GBFS) 🤖

Greedy Best-First Search (GBFS), is a search algorithm that,
instead of expanding the deepest node, like [[Depth-First Search (DFS)]], or the shallowest node, like [[Breadth-First Search (BFS)]],
this algorithm is always going to expand the node that it thinks is closest to the goal.

Now, the search algorithm isn't going to know for sure whether it is the closest thing to the goal, because if we knew what was closest to the goal all the time, then we would already have a solution. Like, the knowledge of what is close to the goal, we could just follow those steps in order to get from the initial position to the solution.
a) The Heuristic Function
But if we don't know the solution-- meaning we don't know exactly what's closest to the goal-- instead, we can use an estimate of what's closest to the goal, otherwise known as a heuristic-- just some way of estimating whether or not we're close to the goal.
And we'll do so using a heuristic function, conventionally called
So what might this heuristic function actually look like in the case of a maze-solving algorithm?

The heuristic function needs to answer a question, like between these two cells, C and D,

which one is better?
Which one would I rather be in if I'm trying to find my way to the goal?
Which one would I rather be in if I'm trying to find my way to the goal?
Well, any human could probably look at this and tell you, you know what? D looks like it's better.

Even if the maze is a convoluted and you haven't thought about all the walls, D is probably better. And why is D better? Well, because if you ignore the wall-- let's just pretend the walls don't exist for a moment and relax the problem, so to speak--
D, just in terms of coordinate pairs, is closer to this goal. It's fewer steps that I would need to take to get to the goal, as compared to C, even if you ignore the walls.

If you just know the x,y coordinate of C, and the x,y coordinate of the goal, and likewise, you know the x,y coordinate of D, you can calculate that D, just geographically, ignoring the walls, looks like it's better.
b) Heuristic Function: The Manhattan Distance 🏙️🚕🗽
And so this is the heuristic function that we're going to use, and it's something called the Manhattan distance (also known as the taxicab distance),

Read more here


The Manhattan distance is one specific type of heuristic, where the heuristic is,
- how many squares vertically and horizontally -- so not allowing myself to go diagonally, just either up or right or left or down.

We need to ask: *How many steps do I need to take to get from each of these cells (C and D) to the goal?
Well, as it turns out, D is much closer. There are fewer steps. It only needs to take six steps in order to get to that goal.

Again here ignoring the walls. We've relaxed the problem a little bit.
We're just concerned with, if you do the math,
- subtract the x values from each other
- and the y values from each other,
what is our estimate of how far we are away?
We can estimate that D is closer to the goal than C is.
And so now we have an approach. We have a way of picking which node to remove from the frontier. And at each stage in our algorithm, we're going to remove a node from the frontier.

We're going to explore the node, if it has the smallest value for this heuristic function, if it has the smallest Manhattan distance to the goal.
C.4.2.2) Using Greedy Best-First Search (GBFS) for the Maze Problem 🔎🧪
And so what would this actually look like?
how do we represent the Manhattan distance in a Maze?
Well, let me first label this graph, label this maze, with a number representing the value of this heuristic function, the value of the Manhattan distance from any of these cells.

Note that from somewhere like here, the Manhattan distance is 2.

We're only two squares away from the goal, geographically, even though in practices we're going to have to take a longer path, but we don't know that yet.

The heuristic is just some easy way to estimate how far we are away from the goal. And maybe our heuristic is overly optimistic.
It thinks that, yeah, we're only two steps away, when in practice, when you consider the walls, it might be more steps.
So the important thing here is that the heuristic isn't a guarantee of how many steps it's going to take. It is estimating. It's an attempt at trying to approximate. And it does seem generally the case that the squares that look closer to the goal have smaller values for the heuristic function than squares that are further away.
So now, using Greedy Best-First Search (GBFS), what might this algorithm actually do? Well, again, for these first five steps, there's not much of a choice. We started this initial state, A. And we say, all right. We have to explore these five states.

But now we have a decision point. Now we have a choice between going left and going right.

Here we can look at 13 and 11 and say that, all right, this square is a distance of 11 away from the goal, according to our heuristic, according to our estimate. And this one we estimate to be 13 away from the goal.
So between those two options, between these two choices, I'd rather have the 11. I'd rather be 11 steps away from the goal, so I'll go to the right.

We're able to make an informed decision because we know a little something more about this problem.
So then we keep following...

Note: between the two sevens. We don't really have much of a way to know between those.

So then we do just have to make an arbitrary choice. And you know what? Maybe we choose wrong.

But that's OK because now we can still say, all right, let's try this seven. and continue....

Now we have another decision point between six and eight.

And between those two-- note, we're also considering the 13, but that's much higher.

Between six, eight, and 13, well, the six is the smallest value, so we'd rather take the six.

Now, we're able to make an informed decision that going this way to the right is probably better than going down that way.
And now we find a decision point where we'll actually make a decision that we might not want to make, but there's unfortunately not too much of a way around this.
We see four and six....

Four looks closer to the goal, right? It's going up, and the goal is further up. So we end up taking that route, which ultimately leads us to a dead end.

But that's OK because we can still say, all right, now let's try the six, and now follow this route that will ultimately lead us to the goal.

And so this now is how Greedy Best-First Search (GBFS), might try to approach this problem, by saying whenever we have a decision between multiple nodes that we could explore, let's explore the node that has the smallest value of
a) Comparing Breadth-First Search (BFS) vs Greedy Best-First Search (GBFS)
And it just so happens that, in this case, we end up doing better, in terms of the number of states we needed to explore, than [[Breadth-First Search (BFS)]] needed to.
This is our exploration with Greedy Best-First Search (GBFS),
Remember that [[Breadth-First Search (BFS)]] explored all of these sections to find a solution,
We were able to eliminate that many steps by taking advantage of this heuristic, this knowledge about how close we are to the goal or some estimate of that idea. So this seems much better.
So wouldn't we always prefer an algorithm like this over an algorithm like [[Breadth-First Search (BFS)]]?
Well, maybe...
One thing to take into consideration is that we need to come up with a good heuristic.
How good the heuristic is is going to affect how good this algorithm is.
And coming up with a good heuristic can oftentimes be challenging.
b) Looking for the Optimal Solution using Greedy Best-First Search (GBFS) - failed attempt
But the other thing to consider is to ask the question, just as we did with the prior two algorithms, is this algorithm optimal?
Will it always find the shortest path from the initial state to the goal?
And to answer that question, let's take a look at this example for a moment.

Again, we're trying to get from A to B, and again, I've labeled each of the cells with their Manhattan distance from the goal, the number of squares up and to the right you would need to travel in order to get from that square to the goal.
And let's think about, would Greedy Best-First Search (GBFS) (that always picks the smallest number) end up finding the optimal solution? What is the shortest solution, and would this algorithm find it?
And the important thing to realize is that right here is the decision point.

We're estimate to be 12 away from the goal. And we have two choices.
- We can go to the left, which we estimate to be 13 away from the goal,
- or we can go up, where we estimate it to be 11 away from the goal.
And between those two, Greedy Best-First Search (GBFS) is going to say, the 11 looks better than the 13.
And in doing so, Greedy Best-First Search (GBFS) will end up finding this path to the goal.

But it turns out this path is not optimal. There is a way to get to the goal using fewer steps. And it's actually this way,

this way that ultimately involved fewer steps, even though it meant at this moment choosing the worst option between the two-- or what we estimated to be the worst option, based on the heuristics.

And so this is what we mean by this is a "greedy" algorithm.
It's making the best decision, locally. At this decision point, it looks like it's better to go here than it is to go to the 13. But in the big picture, it's not necessarily optimal, that it might find a solution when in actuality there was a better solution available.
So we would like some way to solve this problem. We like the idea of this heuristic, of being able to estimate the path, the distance between us and the goal, and that helps us to be able to make better decisions and to eliminate having to search through entire parts of the state space.
But we would like to modify the algorithm so that we can achieve optimality, so that it can be optimal.
And what is the way to do this? What is the intuition here?
Well, let's take a look at this problem. In this initial problem, Greedy Best-First Search (GBFS) found this solution here, this long path.
And the reason why it wasn't great is because, yes, the heuristic numbers went down pretty low,

but later on, and they started to build back up. They built back 8, 9, 10, 11-- all the way up to 12, in this case.

And so how might we go about trying to improve this algorithm?
Well, one thing that we might realize is that, if we go all the way through this path, and we end up going to the 12, and we've had to take this many steps-- like, who knows how many steps that is-- just to get to this 12,
we could have also, as an alternative, taken much fewer steps, just six steps, and ended up at this 13 here.

And yes, 13 is more than 12, so it looks like it's not as good, but it required far fewer steps. Right? It only took six steps to get to this 13 versus many more steps to get to this 12.
And while Greedy Best-First Search (GBFS) says, oh, well, 12 is better than 13 so pick the 12, we might more intelligently say, I'd rather be somewhere that heuristically looks like it takes slightly longer if I can get there much more quickly.
And we're going to encode that idea, this general idea, into a more formal algorithm known as
A star search.
C.4.2.3) Introduction to A* search algorithm 🤖
A star search is going to solve this problem by, instead of just considering the heuristic, also considering how long it took us to get to any particular state.
So the distinction is Greedy Best-First Search (GBFS), if I am in a state right now, the only thing I care about is what is the estimated distance, the heuristic value, between me and the goal.
Heuristic Function Only (Manhattan Distance):
Whereas A star search will take into consideration two pieces of information.
It'll take into consideration,
- how far do I estimate I am from the goal
- but also how far did I have to travel in order to get here (Because that is relevant, too)
So A start search is search algorithm that expands the node with the lowest value of

is that same heuristic that we were talking about a moment ago that's going to vary based on the problem, - but
is going to be the cost to reach the node-- how many steps I had to take, in this case, to get to my current position.

So what does that search algorithm look like in practice? Well, let's take a look. Again, we've got the same maze. And again, I've labeled them with their Manhattan distance.
This value is the

But now, as we begin to explore states, we care not just about this heuristic value but also about

And I care about summing those two numbers together.
- - -
Why is it named like that?

Link: https://stackoverflow.com/questions/29470253/astar-explanation-of-name
a) Using A* Search for the Maze Problem (finding optimal solution) 🔎🧪
So what does that look like?
On this very first step, I have taken one step. And now I am estimated to be 16 steps away from the goal. So the total value here is 17.

Then I take one more step. I've now taken two steps. And I estimate myself to be 15 away from the goal-- again, a total value of 17.

Now I've taken three steps. And I'm estimated to be 14 away from the goal, so on and so forth.

Four steps, an estimate of 13. Five steps, estimate of 12.

And now, here's a decision point. I could either be six steps away from the goal with a heuristic of 13 for a total of 19, or I could be six steps away from the goal with a heuristic of 11 with an estimate of 17 for the total.

So between 19 and 17, I'd rather take the 17-- the 6 plus 11. So so far, no different than what we saw before. We're still taking this option because it appears to be better.

And I keep taking this option because it appears to be better than 6+13 = 19

But it's right about here that things get a little bit different....

Now I could be 15 steps away from the goal with an estimated distance of 6. So 15 plus 6, total value of 21.
Alternatively, I could be six steps away from the goal-- with a total value of 13 as my estimate. So 6 plus 13-- that's 19.
So here we would evaluate
- whereas here, we would be
.
And so the intuition is, 19 less than 21, pick here.
But the idea is ultimately I'd rather be having taken fewer steps to get to a 13 than having taken 15 steps and be at a six because it means I've had to take more steps in order to get there.
Maybe there's a better path this way. So instead we'll explore this route.

Now if we go one more-- this is seven steps plus 14, is 21, so between those two it's sort of a toss up. We might end up exploring that one anyways.

But after that, as these numbers start to get bigger in the heuristic values and these heuristic values start to get smaller, you'll find that we'll actually keep exploring down this path.

and finally we find the optimal solution,

And you can do the math to see that at every decision point, A star search is going to make a choice based on the sum of how many steps it took me to get to my current position and then how far I estimate I am from the goal.
So while we did have to explore some of these states,

the ultimate solution we found was, in fact, an optimal solution.

It did find us the quickest possible way to get from the initial state to the goal.
b) Optimality Conditions for A* Search
And it turns out that A start search is an optimal search algorithm under certain conditions.
So the conditions are:
, my heuristic, needs to be admissible.
What does it mean for a heuristic to be admissible? Well, a heuristic is admissible if it never overestimates the true cost.
So the heuristic value should never overestimate. It should never think that I'm further away from the goal than I actually am.
And the other conditions is:
also needs to be consistent.
And what does it mean for it to be consistent? Mathematically, it means that for every node, which we'll call
So it's a lot of math, but in words, what it ultimately means is that:
- if I am here at this state right now, the heuristic value from me to the goal "
" shouldn't be more than the heuristic value of my successor, the next place I could go to, plus however much it would cost me to just make that step, from one step to the next step " ". - And so this is just making sure that my heuristic is consistent between all of these steps that I might take.
Summary - solution optimal if:

So as long as this is true, then A star search is going to find me an optimal solution.
c) Importance of the Heuristic Design
And this is where much of the challenge of solving these search problems can sometimes come in, that A star search is an algorithm that is known, and you could write the code fairly easily.
But it's choosing the heuristic that can be the interesting challenge. The better the heuristic is, the better I'll be able to solve the problem, and the fewer states that I'll have to explore. And I need to make sure that the heuristic satisfies these particular constraints. So all in all, these are some of the examples of search algorithms that might work.
d) Memory Considerations
And certainly, there are many more than just this. A star search, for example, does have a tendency to use quite a bit of memory, so there are alternative approaches to A star search that ultimately use less memory than this version of A start search happens to use. And there are other search algorithms that are optimized for other cases as well.
_________________________________________________________________
📝Summary of Uninformed & Informed Search Algorithms
Uninformed & Informed Search Algorithms
Search algorithms are fundamental tools in computer science and AI for navigating problem spaces, crucial for tasks like pathfinding, decision-making, and optimization.
Uninformed Search Algorithms
- Definition: Uninformed search algorithms, also known as blind searches, explore the search space without any domain-specific information.
- Key Algorithms:
- Depth-First Search (DFS): Explores as deep as possible along each branch before backtracking. Uses a stack (last-in, first-out). It is memory efficient but does not guarantee the shortest path.
- Breadth-First Search (BFS): Explores all nodes at the current depth level before moving deeper. Uses a queue (first-in, first-out). It guarantees the shortest path in unweighted graphs but can be memory-intensive.
- Uniform Cost Search (UCS): Expands the node with the lowest path cost, ensuring the optimal solution is found. Uses a priority queue.
- Dijkstra's Algorithm: Finds the shortest path from a starting node to all other nodes in a graph with non-negative edge weights. It is similar to UCS and guarantees the optimal solution using a priority queue.
Comparison of Uninformed Search Algorithms:
| Algorithm | Data Structure | Exploration Strategy | Optimality | Memory Usage | Application |
|---|---|---|---|---|---|
| Depth-First Search (DFS) | Stack | Deepest node first | No | Low | Suitable for limited memory, finding any solution |
| Breadth-First Search (BFS) | Queue | Level-wise | Yes (in unweighted graphs) | High | Finding the shortest path |
| Uniform Cost Search (UCS) | Priority Queue | Lowest cost first | Yes | Depends on path costs | Optimal path in weighted graphs |
| Dijkstra's Algorithm | Priority Queue | Lowest cost first | Yes | High | Shortest path in graphs with non-negative weights |
*Informed Search Algorithms:
- Note: Unlike informed algorithms, Dijkstra's Algorithm is an uninformed algorithm as it does not use heuristics but relies solely on edge weights for pathfinding.
- Definition: Informed search algorithms use additional problem-specific knowledge (heuristics) to make the search process more efficient.
- Key Algorithms:
- Greedy Best-First Search (GBFS): Uses a heuristic function to choose the node that appears closest to the goal. It is faster but does not guarantee the optimal solution.
- A Search*: Combines the cost to reach the current node (g(n)) and an estimated cost to the goal (h(n)). It guarantees the optimal solution if the heuristic is admissible (does not overestimate the true cost).
- Iterative Deepening A (IDA)**: A memory-efficient version of A* that uses iterative deepening with heuristics.
- Weighted A*: A variant of A* that allows faster solutions by relaxing optimality to some extent, using a weighted heuristic.
Comparison of Informed Search Algorithms:
| Algorithm | Data Structure | Exploration Strategy | Optimality | Memory Usage | Application |
|---|---|---|---|---|---|
| Greedy Best-First Search | Priority Queue | Closest to goal (heuristic) | No | Typically higher than DFS | Faster search with heuristic guidance |
| A Search* | Priority Queue | Combines cost and heuristic (g(n) + h(n)) | Yes (if heuristic is admissible) | Higher memory usage than DFS/BFS | Optimal pathfinding with admissible heuristic |
| Iterative Deepening A* | Stack + Heuristic | Iterative deepening with heuristic | Yes (if heuristic is admissible) | Lower memory usage compared to A* | Memory-efficient optimal search |
| Weighted A* | Priority Queue | Weighted heuristic | No (faster but less accurate) | Similar to A* | Faster solutions with less strict optimality |
Conclusion:
Both uninformed (DFS, BFS, UCS, Dijkstra's) and informed (e.g., GBFS, A*, IDA*) algorithms are essential for solving different types of problems. Uninformed searches explore without guidance, while informed searches use heuristics to improve efficiency. The choice of algorithm depends on the specific problem, whether optimality is required, and the availability of heuristic information.
Quick Reference:
- Dijkstra's Algorithm: Finds the shortest path in graphs with non-negative weights, guarantees optimality.
- DFS: Explores deeply first, memory-efficient, not always optimal.
- BFS: Explores level by level, guarantees shortest path, high memory usage.
- UCS: Finds the lowest cost path, guarantees optimality.
- GBFS: Uses heuristics for quick decisions, not always optimal.
- A Search*: Combines path cost and heuristic, guarantees optimality with admissible heuristic.
- IDA*: Iterative version of A*, reduces memory usage compared to A*.
🔗 Related Content
a) Flood Fill Algorithm
Video: https://youtu.be/ZMQbHMgK2rw
b) Any-Angle Pathfinding
Video: https://youtu.be/7MOQOvGJyn4
Video: https://youtu.be/LvkyXdqpqHw
Z) 🗃️ Glossary
| File | Definition |
|---|